The internet is a vast network of interconnected data, powering industries and transforming businesses globally. However, the same openness that makes the internet so valuable also makes it vulnerable. One growing threat is web scraping, where unauthorized entities extract valuable data from websites without permission. While web scraping can sometimes serve legitimate purposes, such as for research or search engine indexing, malicious actors often misuse it to steal competitive intelligence, customer data, and proprietary information. Understanding the methods behind web scraping and implementing protective measures is critical for every website owner. This comprehensive guide will walk you through the risks of web scraping, how to detect it, and the best strategies to prevent it.
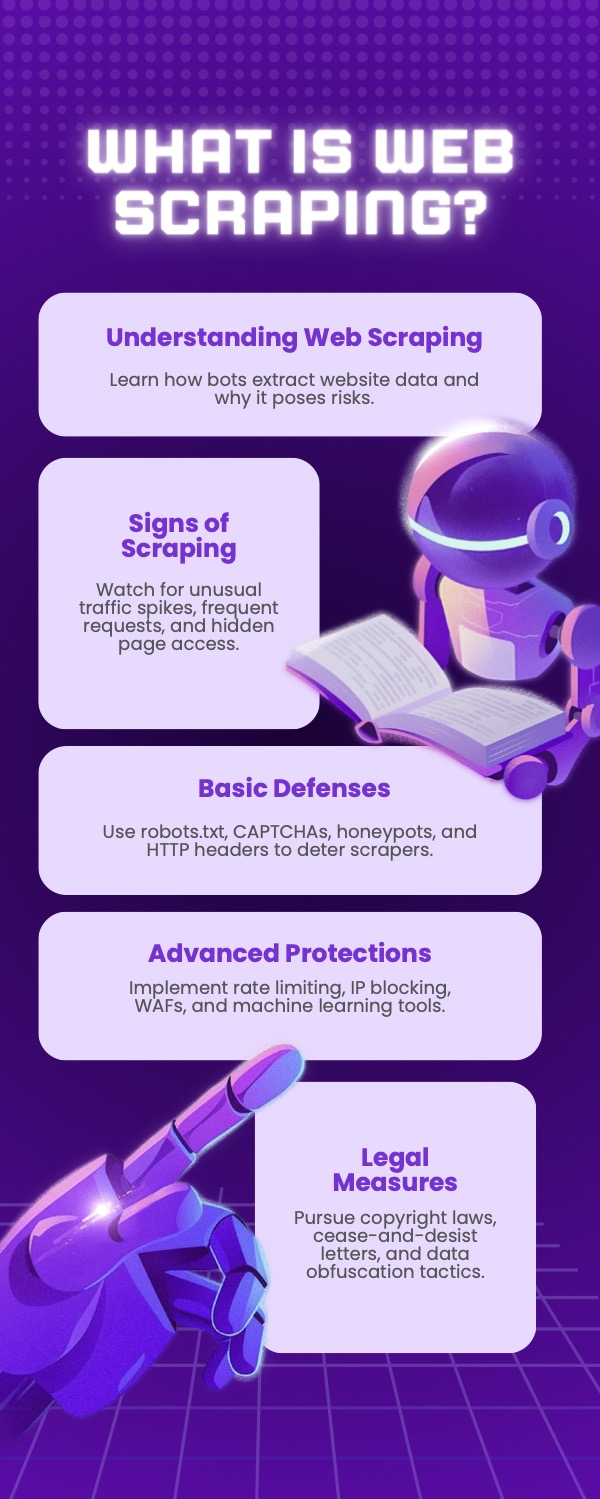
What Is Web Scraping, and Why Is It a Threat?
At its core, web scraping is the process of extracting data from websites using proxies and automated tools. Scrapers bypass the normal flow of accessing information, enabling them to collect data in bulk without permission. For legitimate purposes, web scraping helps businesses track pricing trends or analyze competitors. However, when used maliciously, it can:
- Steal sensitive pricing strategies.
- Harvest user data, such as email addresses or login details.
- Repurpose your content on other platforms without consent.
The Financial Toll of Web Scraping
The financial implications of web scraping are severe. In 2022, businesses globally reported over $3.5 billion in losses tied to data breaches. This doesn’t include the indirect costs, such as reputational damage, legal battles, or loss of customer trust, all of which compound the harm caused by scraping-related breaches.
Why Website Data Protection Matters

Protecting website data is about more than keeping sensitive details secure. It’s about maintaining the integrity of your business, preserving your competitive edge, and safeguarding user trust. A company’s failure to implement adequate security measures can lead to:
- Reputational Damage: Once customers lose faith in your ability to protect their data, rebuilding trust can take years.
- Operational Challenges: Competitors using your stolen data can undercut your pricing or replicate your strategies.
- Legal Liability: Companies that fail to protect user data may face penalties under laws like GDPR or the Computer Fraud and Abuse Act.
By implementing robust protective measures, you can secure your website and foster long-term growth.
How Does Web Scraping Work?
Understanding how web scraping works is the first step in defending against it.
Common Web Scraping Techniques
- Bots and Crawlers: Automated programs that systematically browse websites and extract data at high speeds. These bots often use proxy servers to mask their IP addresses and avoid detection. By rotating proxies, scrapers can appear to be multiple unique users, bypassing rate-limiting and IP blocking measures.
- Manual Scraping: While less common, humans may manually copy and paste data, especially for highly targeted content. In some cases, they may also use a proxy to conceal their true identity or location while accessing restricted or region-specific content.
Proxies play a crucial role in enabling web scraping, as they allow scrapers to evade detection, circumvent geo-restrictions, and maintain anonymity. Understanding the role of proxies in scraping techniques is key to implementing effective defenses, such as detecting unusual proxy traffic or blocking known proxy IP ranges.
Signs Your Website Is Being Scraped
Web scraping activities often leave traces. Some warning signs include:
- Sudden Traffic Spikes: An unusual surge in traffic, especially from unknown sources or specific IP addresses, can indicate scraping attempts.
- High Request Volumes: Scrapers often send hundreds or thousands of requests to your server within a short timeframe.
- Accessing Non-Public Pages: Repeated attempts to reach private or hidden sections of your website may signal malicious intent.
By actively monitoring these patterns, you can detect scraping attempts early.
Best Practices for Preventing Web Scraping
- Use Robots.txt: The robots.txt file acts as an instruction manual for web crawlers, specifying which areas of your site they can and cannot access. For example:
- Leverage HTTP Headers: Implement HTTP headers such as X-Robots-Tag to limit how search engines and other bots interact with specific files or pages. This adds an extra layer of control.
- Implement CAPTCHAs: Adding CAPTCHAs, reCAPTCHAs or Turnstile to critical sections of your site ensures that only humans can proceed. This is particularly effective for login pages, contact forms, or areas with sensitive data.
- Use Honeypots: Honeypots are invisible fields placed within your website that only bots can see. When bots interact with these fields, they reveal their presence, allowing you to block them effectively.
User-agent: * Disallow: /private/
While this measure is helpful for ethical crawlers, it is not foolproof since malicious scrapers often ignore these directives.

Advanced Strategies to Prevent Web Scraping
Rate Limiting and IP Blocking
- Rate Limiting: Restrict the number of requests a single IP can make within a specific timeframe. For example, allow only 10 requests per minute per user.
- IP Blocking: Monitor traffic and block suspicious IP addresses or ranges. Many scraping bots originate from data centers or hosting services, which can be preemptively blocked.
Web Application Firewall (WAF)
A Web Application Firewall protects your site by filtering incoming traffic. Advanced WAFs come with features like bot detection, preventing scrapers from accessing your content in real time.
Bot Management Tools
Bot management services are specialized solutions designed to detect, analyze, and mitigate automated bot traffic on websites, mobile apps, and APIs. These services use advanced techniques such as machine learning, behavioral analysis, and device fingerprinting to differentiate between legitimate users and malicious bots. Popular solutions include Cloudflare Bot Management, Akamai Bot Manager, PerimeterX Bot Defender, Imperva Advanced Bot Protection, and DataDome.
By blocking harmful activities like web scraping, credential stuffing, and fake account creation, bot management services protect sensitive data, preserve website performance, and maintain user trust. They also offer tools like rate limiting, CAPTCHAs, and IP reputation analysis to prevent abuse.
Legal and Preventive Measures
- Understand Data Protection Laws: Legislation like GDPR (General Data Protection Regulation) and the Computer Fraud and Abuse Act (CFAA) provides legal recourse against web scrapers. Ensure your website complies with these laws and understand your rights.
- Pursue Legal Action: If scraping activities cause significant harm, consider pursuing legal action. Begin with cease-and-desist letters, and escalate to lawsuits if necessary.
- Obfuscate Your Data: Make your data less accessible by:
- Altering its structure.
- Requiring JavaScript to load critical information, which many bots cannot parse.
- Using encryption techniques for sensitive fields.
A Multi-Layered Approach to Web Scraping Prevention
Preventing web scraping requires combining technical, strategic, and legal defenses. Here’s a quick summary of actionable steps:
- Set up a robots.txt file and HTTP headers to limit access.
- Add CAPTCHAs and honeypots to deter bots.
- Monitor traffic patterns for unusual activity.
- Use rate limiting, IP blocking, and WAFs to restrict unauthorized access.
- Leverage AI to stay ahead of evolving scraping techniques.
The methods used by web scrapers evolve rapidly. Regularly updating your website’s defenses ensures you remain one step ahead.
Conclusion
Web scraping presents a significant challenge for website owners, often leading to data breaches, financial losses, and reputational damage. While understanding the methods and motivations behind web scraping is crucial, protecting your website requires a multi-layered approach that combines technical solutions, like CAPTCHAs, honeypots, and Web Application Firewalls.
By leveraging advanced tools like bot management services and monitoring traffic patterns for unusual activity, businesses can stay one step ahead of malicious scrapers. Continuous vigilance, combined with robust defenses, not only safeguards sensitive data but also preserves user trust and ensures long-term success in an increasingly competitive online environment.
Share this post
Leave a comment
All comments are moderated. Spammy and bot submitted comments are deleted. Please submit the comments that are helpful to others, and we'll approve your comments. A comment that includes outbound link will only be approved if the content is relevant to the topic, and has some value to our readers.
Comments (0)
No comment